Graph infrastructure for agents.
Trellis is a local-first graph where your notes, code, and agents live in one substrate you own. Every view is a projection. Every change is remembered.
Opens Trellis Studio in your browser. Local-first by default.
Primitives
Interactive engine demos.
Causal ops, sync, realtime mesh, and graph queries. Studio is the workspace layer on top. Studio overview.
Persisted
Agentic state
Todos as projections; VcsOps chained in a merged DAG. MemorySyncRoom sync.
Try the demoEphemeral
Chat + graph
Peers and messages as entities. Labeled edges for broadcast and presence.
Try the demoQuery
EQL-S playground
Run graph queries on a fixture workspace; see matches light up.
Run queriesRealtime
Presence & mesh
Avatars, cursors, CRDT text. Not written to the op log.
ExploreTyped SDK
Live graph reads
defineType → liveEntities. Vue, React, Svelte hooks on persisted entities.
Read the guideThe problem
Work lives in apps that don't share data.
Apps are silos
The same information lives in five tools that don't talk to each other, and each one forgets everything the moment it closes. In Trellis it's one graph. A board, a table, a timeline are projections over the same entities. Change the projection and the view changes. The data stays.
Reasoning isn't persisted
Every change has a reason, and almost all of them die in PR comments, chat threads, and somebody's memory. Agents make it worse: they decide and act all day, and none of it survives the session. In Trellis, reasoning is data: decisions are entities, linked to the files they touched.
Data sits in vendor systems
Your identity is a row in someone else's database; your history belongs to someone else's audit log. In Trellis your identity is a keypair you generated and your data is files on your device. Move it anywhere. Nothing is held hostage.
The substrate
One graph. Every view is a projection over it.
Trellis is a local-first graph engine. Notes, files, tasks, and agent runs live in the graph as entities. Every change is an op: immutable, content-addressed, causally chained. Every decision (human or AI) is a record with a reason. History is a query, not a scroll. The whole thing lives in a .trellis/ folder you can back up with cp -r.
The substrate doesn't care whether the entity is code or notes or agent reasoning. It holds everything in the same shape.
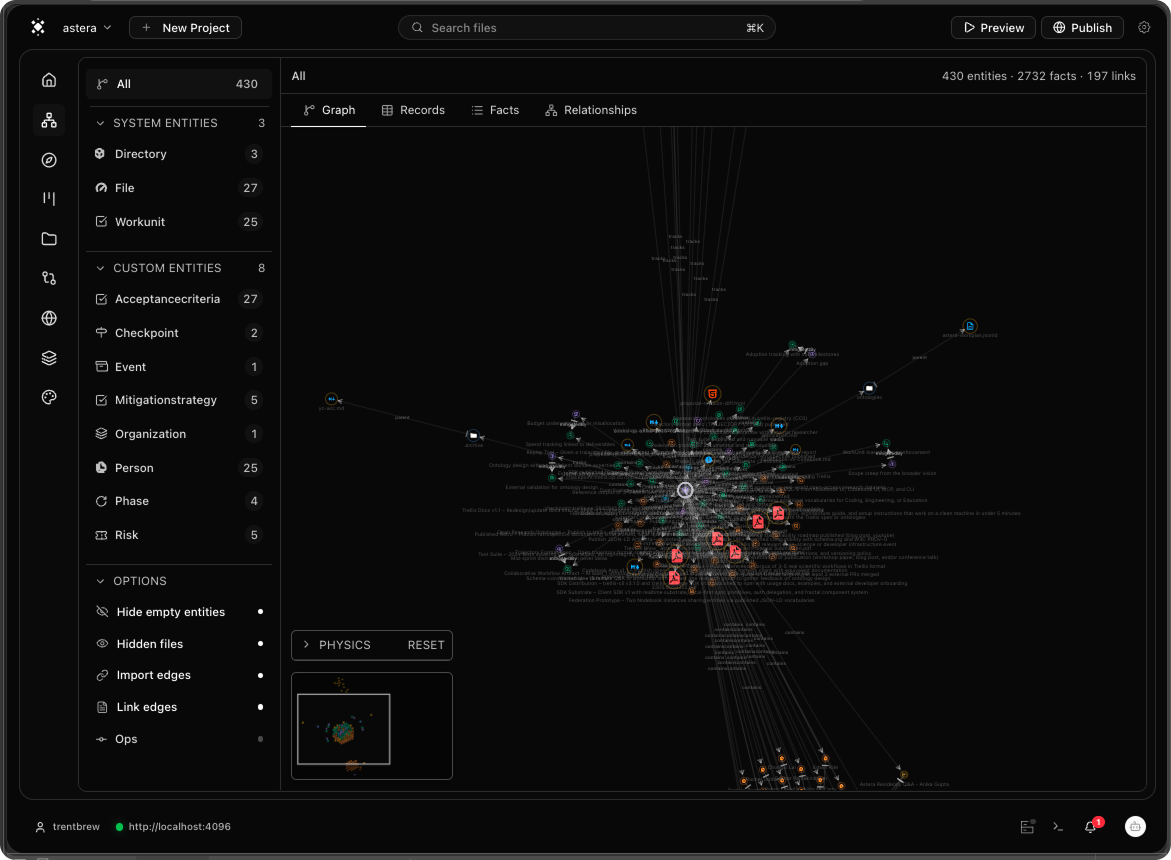
Studio
Studio is the workspace layer.
The engine runs by itself. Trellis Studio is the workspace over it: graph, editor, history, agents, decisions, and issues on the same substrate. Boots with npx trellis studio.
Architecture
How it's built
Three parts. Each does one job. Together they let one graph hold code, reasoning, and history in the same shape.
Part 1
The Graph Engine
Trellis is an EAV store (entities, attributes, values) plus a link index. Files, decisions, issues, and agent runs are all entities with stable IDs.
A fact
{ e: "decision:DEC-42", a: "rationale", v: "SEV-1 precedent + finance exception" }A link
{ e1: "decision:DEC-42", a: "affects", e2: "file:src/auth/session.ts" } Mutations produce immutable ops, content-addressed and causally chained. Reading the history of a file isn't git log. It's a graph query: what decisions affected this file, made by which agents, against what alternatives?

Part 2
The Agent Harness
Studio turns agent runs into durable graph ops. Every tool call is structured data in the same substrate as the code it changed, not another chat log to embed later.
Part 3
The Filesystem
The whole engine fits in a .trellis/ folder. SQLite for kernel state, JSON for entity collections, content-addressed blobs for ops. The filesystem is the source of truth; the graph is a materialized view, rebuilt on startup.
Backup is cp -r. Sync is optional. There's a server you can run for collaboration, but it's the second-best mode. The first-best mode is your machine.
Agent memory
One graph for agents and humans.
Durable agent memory needs structure, not just a longer context window. Teams need agents that can return to prior decisions and act on them days later. Most agents lose that context when the session ends.
The current answers are all RAG over the agent's own output. Store the chat log, embed it, retrieve relevant fragments. This works for vibes-level recall. It fails the moment you need anything causal: which decisions affected the auth subsystem last quarter and were later reversed? That's a graph query, not a similarity search.
The way through is a structure that's legible to both the agent and you. If those are different systems, they desync. If they're the same graph, the agent's reasoning is recorded in the execution path, not reconstructed after, and lands in the same shape as the codebase it's modifying. One graph, two kinds of readers.
Local-first
Offline by default
Kill the wifi. Everything still works: the graph, the queries, the history, Studio. Sync is additive: it connects graphs, it never owns them. If a feature would break offline, it doesn't ship.
Principles
- Data over applications. If a feature traps data in one view, it doesn't ship.
- Append-only over mutable. History is never rewritten. Time travel is a primitive, not a feature.
- Local-first, cloud-optional. If the cloud becomes load-bearing, that's a bug.
- Agents are auditable peers. Same identity system, same rules, every decision traced.
Install
Get started
Install locally. No account required.
Requires Node 18+ and git.